Stage : ÉCOLE NATIONALE DE LA MÉTÉOROLOGIE – Développement et évaluation d’un passage à l’échelle des prévisions Arome sur l’Europe avec des méthodes d’Intelligence Artificielle Générative – 25 octobre, 2024
1) Description du sujet – livrables attendus
L’utilisation de l’intelligence artificielle (IA) pour la Prévision Numérique du Temps (PNT) se démocratise progressivement depuis plusieurs années. Les algorithmes d’apprentissage profond et les approches génératives ont d’ailleurs récemment fait leur preuve dans ce domaine d’application. Désormais, ces méthodes ont la capacité de produire des champs physiques avec une certaine cohérence physique, pour un coût numérique très inférieur aux méthodes classiques d’intégration numérique.
Le stage proposé se place dans le cadre de Destination Earth (DestinE). DestinE est une initiative de la Commission européenne dans le cadre du programme EU Digital Europe. Ce projet vise à déployer plusieurs jumeaux numériques de la Terre, qui aideront à surveiller et à prévoir les changements environnementaux et l’impact humain, afin de développer et de tester des scénarios qui soutiendraient le développement durable et les politiques européennes correspondantes pour le Green Deal. L’IA, et en particulier l’apprentissage profond, sont un des axes développés dans DestinE.
Le travail durant le stage sera à destination du projet DE_371, auquel l’équipe d’accueil participe. L’objectif du projet DE_371 est de démontrer que des méthodologies utilisant les algorithmes d’IA à l’état de l’art peuvent aider à améliorer l’estimation de l’incertitude des prévisions, en permettant de produire des prévisions d’ensemble de grande taille et à haute résolution spatiale et temporelle.
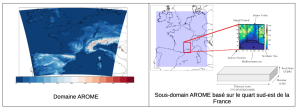
L’objectif du travail proposé est d’utiliser des techniques d’IA dites génératives comme les Réseaux Antagonistes Génératifs (GAN) [1] pour améliorer les performances du système opérationnel de prévision d’ensemble Arome. L’équipe d’accueil a développé un prototype StyleGAN [2][3] capable de générer des membres Arome physiquement cohérents sur un quart sud-est de la France et pour quelques variables de surface. Ce stage se propose d’utiliser ce prototype comme base de développement. Les résultats encourageants mènent vers plusieurs pistes d’approfondissement et d’amélioration, qui feront l’objet du présent stage, parmi lesquelles :
-
Adaptation du modèle à une extension du domaine actuel.
-
Exploration de méthodes de Transfer Learning [4] sur le domaine nordique (Norvège, Suède).
-
Evaluation des prévisions StyleGAN sur des évènements à fort impact.
Le ou la stagiaire pourra disposer de moyens de calculs sur GPU importants (plate-forme Météo France et/ou super-calculateur EuroHPC), au sein d’une équipe expérimentée et motivée. Il ou elle bénéficiera des outils et méthodes déjà développés dans l’équipe. Ce stage sera l’occasion de développer ses compétences, notamment :
-
expérience de développement d’algorithmes d’apprentissage profond à l’état de l’art
-
manipulation d’une infrastructure de calcul haute-performance
-
gestion d’une base de code commune et ajout de fonctionnalités
-
intéractions avec des partenaires internationaux (centres météorologiques en Norvège et Suède)
Ce stage requiert un réel intérêt pour la prévision numérique du temps (des connaissances préalable à ce sujet seraient un plus mais ne sont pas nécessaire). De solides compétences en statistiques et une bonne maîtrise du langage Python seront également nécessaires. Une connaissance préalable du fonctionnement des réseaux de neurones profonds (en particulier des réseaux convolutifs CNN) est souhaitée. Une première expérience d’une bibliothèque de Deep Learning (PyTorch, TensorFlow, …) serait un plus.
Livrables attendus : codes, rapport, support de soutenance.
2) Lieu du stage, durée ou période
Ce stage de 6 mois se déroulera dans l’équipe Prévisibilité du Centre National de Recherche Météorologique (CNRM), à Toulouse. Des réunions régulières avec les ingénieurs du projet seront organisées.
3) Références bibliographiques
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139-144. https://dl.acm.org/doi/pdf/10.1145/3422622.
[2] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2020). Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8110-8119).https://openaccess.thecvf.com/content_CVPR_2020/papers/ Karras_Analyzing_and_Improving_the_Image_Quality_of_StyleGAN_CVPR_2020_paper.pdf
[3] Brochet, C., Raynaud, L., Thome, N., Plu, M., & Rambour, C. (2023). Multivariate Emulation of Kilometer-Scale Numerical Weather Predictions with Generative Adversarial Networks: A Proof of Concept. Artificial Intelligence for the Earth Systems, 2(4), 230006. https://doi.org/10.2496.
[4] Lee, D., Lee, J. Y., Kim, D., Choi, J., & Kim, J. (2022). Fix the noise: Disentangling source feature for transfer learning of StyleGAN. arXiv preprint arXiv:2204.14079. https://arxiv.org/pdf/2204.14079
Type de contrat : stage
Durée du contrat : 6 mois
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : CNRM Toulouse et à distance
Quotité du travail : 100%
Supervision :
Victor Sanchez (CNRM), Angélique Bonamy (CNRM) et Laure Raynaud (CNRM)
Pour postuler
Adresser CV + lettre de motivation :
victor.sanchez@meteo.fr
Stage : EXPLORATION DES SYNERGIES ENTRE MÉTHODES STATISTIQUES ET FORMELLES POUR L’EXPLICABILITÉ DE L’INTELLIGENCE ARTIFICIELLE – 21 octobre, 2024
Dans ce stage, nous nous pencherons sur la synergie entre deux domaines essentiels de l’explicabilité de l’intelligence artificielle : L’explicabilité statistique et l’explicabilité formelle. L’explicabilité statistique, en particulier par l’attribution de caractéristiques, a été la pierre angulaire de l’identification des caractéristiques significatives contribuant à une prédiction. Cette méthode s’est avérée efficace pour diverses architectures neuronales, offrant une évolutivité et une application généralisée.
Cependant, le manque de garanties dans les méthodes statistiques a limité leur utilisation pratique dans l’industrie. Pour y remédier, notre projet de stage propose une analyse comparative des cartes de caractéristiques générées par les méthodes statistiques et les méthodes formelles. En examinant ces deux familles de techniques d’explicabilité, nous visons à combler le fossé entre la robustesse théorique et l’applicabilité pratique.
Ce projet sera évalué à l’aide d’un ensemble de données industrielles libres axées sur des scénarios d’atterrissage visuels. Les résultats pourraient potentiellement améliorer la fiabilité et la capacité d’action des méthodes d’explicabilité dans les applications du monde réel.
Idéalement, ce stage d’une durée de 6 mois commencera en Mars 2025 (la période est communiquée à titre indicatif, et pourra être revue).
Tasks and Accountabilities :
Votre tuteur/tutrice vous aidera à identifier vos objectifs professionnels et vous accompagnera dans le développement de vos compétences.
Vos principales activités seront les suivantes :
- Conduire un état de l’art des méthodes d’explicabilité statistique et formelle.
- Développer les algorithmes de mise en pratique des méthodes les plus pertinentes.
- Appliquer les méthodes à un cas d’usage industrie
Ce stage vous permettra notamment de développer les compétences suivantes :
- Connaissance des différentes méthodes d’explicabilité pour l’intelligence artificielle.
- Développement dans un cadre d’application industriel.
- Travail en équipe.
Required skills
Vous préparez actuellement un diplôme de niveau Bac +5 dans le domaine de l’intelligence artificielle ou une discipline apparentée?
Vous possédez les compétences suivantes :
-
- Expérience en python et framework Machine Learning/Deep Learning (e.g. Keras/Tensorflow)
- Expérience sur certaines méthodes d’explicabilité
- Excellent niveau de communication, travail d’équipe
Compétences linguistiques :
- Anglais : Intermédiaire
- Français : Avancé
Type de contrat : stage
Durée du contrat : 6 months
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : Toulouse
Quotité du travail : 100%
Supervision :
Boumazouza Ryma (Airbus) et Ducoffe Mélanie (Airbus)
Pour postuler
Adresser CV + lettre de motivation :
ryma.boumazouza@airbus.com
melanie.ducoffe@airbus.com
Internship : FORMAL VERIFICATION OF MACHINE LEARNING ALGORITHMS ON ADVANCED AVIONICS HARDWARE – October 15, 2024
Machine Learning (ML) plays a pivotal role in the development of autonomous systems, including future generations of aircraft that will integrate advanced algorithms for enhanced capabilities, such as vision-based autonomous landing for drones and commercial aircraft. While these algorithms perform efficiently in cloud or data center environments, deploying them on autonomous vehicles presents significant challenges—especially in ensuring safety. In the field of aeronautics, every function, whether ML-based or not, must meet rigorous safety standards, even in the event of hardware failures.
Vision-based perception systems, which are critical for autonomous operations, demand immense computational power and high-bandwidth communications (e.g., from cameras). However, current avionics processors lack the necessary capacity to handle such workloads. As a result, new processing architectures, such as Component-off- the-shelf (COTS) GPUs and many-core processors, will be essential. Before these can be deployed, it’s crucial to study their hardware failure modes, understand how these failures could affect the ML algorithms they support, and develop safeguards to ensure safe execution.
Several existing works, such as [1], [2], and [3], have addressed these issues by formally modeling platform behavior in the presence of faults, along with the mitigation strategies designed to reduce the impact of these faults. These models can be analyzed using solvers to determine if the mitigations are sufficient to guarantee safe hardware operation under specified conditions.
Preliminary research has identified the Versatile Tensor Accelerator (VTA [4]) as a suitable candidate for further exploration of this problem. VTA is open hardware, meaning its hardware description is fully accessible and customizable. It is described using Chisel [5], an advanced high-level hardware description language built on Scala [6].
[1] Guinebert, I., Barrilado, A., Delmas, K., Galtié, F., & Pagetti, C. (2022, June). Quality of Fault Injection Strategies on Hardware Accelerator. In International Conference on Computer Safety, Reliability, and Security (pp. 222-236). Cham: Springer International Publishing.
[2]Faure-Gignoux, A, Delmas, K, Gauffriau, A, Pagetti, C. (2024) Methodology for formal verification of hardware.safety strategies using SMT. International conference on embedded software (EMSOFT)
[3] Dobis, A., Laeufer, K., Damsgaard, H. J., Petersen, T., Rasmussen, K. J. H., Tolotto, E., … & Schoeberl, M. (2023). Verification of chisel hardware designs with chiselverify. Microprocessors and Microsystems, 96, 104737.
[4] https://github.com/apache/tvm-vta [5] https://www.chisel-lang.org/
Tasks and Accountabilities :
The primary goal of this internship is to evaluate the effectiveness of a set of pre-selected formal verification methods on the VTA. The key steps include:
-
- Conducting a literature review to identify the most promising formal verification methods from the pre- selected set.
- Gaining proficiency with the toolset required for functional and cycle-accurate simulation of VTA executions.
- Developing a framework to run small portions of deep neural networks (DNNs) on both functional and cycle-accurate simulators.
- Extending the framework to verify formal properties using the selected methods.
- Assessing the expressiveness and scalability of the approach, initially focusing on specific parts of theVTA, and, if feasible, expanding to the full accelerator.
- Based on the experiments, formulating recommendations for future theoretical and practicaldevelopments required for full-scale safety validation of VTA-like accelerators.
Required skills
-
- Hardware description languages (advanced)
- Compilation, Computing architectures (intermediate)
- Formal verification (notions)
- Programming (advanced)
Desired period
March to September 2025
Type de contrat : stage
Durée du contrat : 5-6 months (march to September 2025)
Gratification : 624,22€/month
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : ONERA Toulouse: 2 Av. Marc Pélegrin, 31000 Toulouse. (Toulouse)
Quotité du travail : 100%
Supervision :
Kevin Delmas (ONERA) and Anthony Faure-Gignoux (ONERA)
Pour postuler
Adresser CV + lettre de motivation :
Kevin.delmas@onera.fr
Anthony.faure-gignoux@onera.fr
Stage : ÉCOLE NATIONALE DE LA MÉTÉOROLOGIE – Développement et évaluation d’un passage à l’échelle des prévisions Arome sur l’Europe avec des méthodes d’Intelligence Artificielle Générative – 25 octobre, 2024
1) Description du sujet – livrables attendus
L’utilisation de l’intelligence artificielle (IA) pour la Prévision Numérique du Temps (PNT) se démocratise progressivement depuis plusieurs années. Les algorithmes d’apprentissage profond et les approches génératives ont d’ailleurs récemment fait leur preuve dans ce domaine d’application. Désormais, ces méthodes ont la capacité de produire des champs physiques avec une certaine cohérence physique, pour un coût numérique très inférieur aux méthodes classiques d’intégration numérique.
Le stage proposé se place dans le cadre de Destination Earth (DestinE). DestinE est une initiative de la Commission européenne dans le cadre du programme EU Digital Europe. Ce projet vise à déployer plusieurs jumeaux numériques de la Terre, qui aideront à surveiller et à prévoir les changements environnementaux et l’impact humain, afin de développer et de tester des scénarios qui soutiendraient le développement durable et les politiques européennes correspondantes pour le Green Deal. L’IA, et en particulier l’apprentissage profond, sont un des axes développés dans DestinE.
Le travail durant le stage sera à destination du projet DE_371, auquel l’équipe d’accueil participe. L’objectif du projet DE_371 est de démontrer que des méthodologies utilisant les algorithmes d’IA à l’état de l’art peuvent aider à améliorer l’estimation de l’incertitude des prévisions, en permettant de produire des prévisions d’ensemble de grande taille et à haute résolution spatiale et temporelle.
L’objectif du travail proposé est d’utiliser des techniques d’IA dites génératives comme les Réseaux Antagonistes Génératifs (GAN) [1] pour améliorer les performances du système opérationnel de prévision d’ensemble Arome. L’équipe d’accueil a développé un prototype StyleGAN [2][3] capable de générer des membres Arome physiquement cohérents sur un quart sud-est de la France et pour quelques variables de surface. Ce stage se propose d’utiliser ce prototype comme base de développement. Les résultats encourageants mènent vers plusieurs pistes d’approfondissement et d’amélioration, qui feront l’objet du présent stage, parmi lesquelles :
-
Adaptation du modèle à une extension du domaine actuel.
-
Exploration de méthodes de Transfer Learning [4] sur le domaine nordique (Norvège, Suède).
-
Evaluation des prévisions StyleGAN sur des évènements à fort impact.
Le ou la stagiaire pourra disposer de moyens de calculs sur GPU importants (plate-forme Météo France et/ou super-calculateur EuroHPC), au sein d’une équipe expérimentée et motivée. Il ou elle bénéficiera des outils et méthodes déjà développés dans l’équipe. Ce stage sera l’occasion de développer ses compétences, notamment :
-
expérience de développement d’algorithmes d’apprentissage profond à l’état de l’art
-
manipulation d’une infrastructure de calcul haute-performance
-
gestion d’une base de code commune et ajout de fonctionnalités
-
intéractions avec des partenaires internationaux (centres météorologiques en Norvège et Suède)
Ce stage requiert un réel intérêt pour la prévision numérique du temps (des connaissances préalable à ce sujet seraient un plus mais ne sont pas nécessaire). De solides compétences en statistiques et une bonne maîtrise du langage Python seront également nécessaires. Une connaissance préalable du fonctionnement des réseaux de neurones profonds (en particulier des réseaux convolutifs CNN) est souhaitée. Une première expérience d’une bibliothèque de Deep Learning (PyTorch, TensorFlow, …) serait un plus.
Livrables attendus : codes, rapport, support de soutenance.
2) Lieu du stage, durée ou période
Ce stage de 6 mois se déroulera dans l’équipe Prévisibilité du Centre National de Recherche Météorologique (CNRM), à Toulouse. Des réunions régulières avec les ingénieurs du projet seront organisées.
3) Références bibliographiques
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2020). Generative adversarial networks. Communications of the ACM, 63(11), 139-144. https://dl.acm.org/doi/pdf/10.1145/3422622.
[2] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2020). Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8110-8119).https://openaccess.thecvf.com/content_CVPR_2020/papers/ Karras_Analyzing_and_Improving_the_Image_Quality_of_StyleGAN_CVPR_2020_paper.pdf
[3] Brochet, C., Raynaud, L., Thome, N., Plu, M., & Rambour, C. (2023). Multivariate Emulation of Kilometer-Scale Numerical Weather Predictions with Generative Adversarial Networks: A Proof of Concept. Artificial Intelligence for the Earth Systems, 2(4), 230006. https://doi.org/10.2496.
[4] Lee, D., Lee, J. Y., Kim, D., Choi, J., & Kim, J. (2022). Fix the noise: Disentangling source feature for transfer learning of StyleGAN. arXiv preprint arXiv:2204.14079. https://arxiv.org/pdf/2204.14079
Type de contrat : stage
Durée du contrat : 6 mois
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : CNRM Toulouse et à distance
Quotité du travail : 100%
Supervision :
Victor Sanchez (CNRM), Angélique Bonamy (CNRM) et Laure Raynaud (CNRM)
Pour postuler
Adresser CV + lettre de motivation :
victor.sanchez@meteo.fr
Stage : EXPLORATION DES SYNERGIES ENTRE MÉTHODES STATISTIQUES ET FORMELLES POUR L’EXPLICABILITÉ DE L’INTELLIGENCE ARTIFICIELLE – 21 octobre, 2024
Dans ce stage, nous nous pencherons sur la synergie entre deux domaines essentiels de l’explicabilité de l’intelligence artificielle : L’explicabilité statistique et l’explicabilité formelle. L’explicabilité statistique, en particulier par l’attribution de caractéristiques, a été la pierre angulaire de l’identification des caractéristiques significatives contribuant à une prédiction. Cette méthode s’est avérée efficace pour diverses architectures neuronales, offrant une évolutivité et une application généralisée.
Cependant, le manque de garanties dans les méthodes statistiques a limité leur utilisation pratique dans l’industrie. Pour y remédier, notre projet de stage propose une analyse comparative des cartes de caractéristiques générées par les méthodes statistiques et les méthodes formelles. En examinant ces deux familles de techniques d’explicabilité, nous visons à combler le fossé entre la robustesse théorique et l’applicabilité pratique.
Ce projet sera évalué à l’aide d’un ensemble de données industrielles libres axées sur des scénarios d’atterrissage visuels. Les résultats pourraient potentiellement améliorer la fiabilité et la capacité d’action des méthodes d’explicabilité dans les applications du monde réel.
Idéalement, ce stage d’une durée de 6 mois commencera en Mars 2025 (la période est communiquée à titre indicatif, et pourra être revue).
Tasks and Accountabilities :
Votre tuteur/tutrice vous aidera à identifier vos objectifs professionnels et vous accompagnera dans le développement de vos compétences.
Vos principales activités seront les suivantes :
- Conduire un état de l’art des méthodes d’explicabilité statistique et formelle.
- Développer les algorithmes de mise en pratique des méthodes les plus pertinentes.
- Appliquer les méthodes à un cas d’usage industrie
Ce stage vous permettra notamment de développer les compétences suivantes :
- Connaissance des différentes méthodes d’explicabilité pour l’intelligence artificielle.
- Développement dans un cadre d’application industriel.
- Travail en équipe.
Required skills
Vous préparez actuellement un diplôme de niveau Bac +5 dans le domaine de l’intelligence artificielle ou une discipline apparentée?
Vous possédez les compétences suivantes :
-
- Expérience en python et framework Machine Learning/Deep Learning (e.g. Keras/Tensorflow)
- Expérience sur certaines méthodes d’explicabilité
- Excellent niveau de communication, travail d’équipe
Compétences linguistiques :
- Anglais : Intermédiaire
- Français : Avancé
Type de contrat : stage
Durée du contrat : 6 months
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : Toulouse
Quotité du travail : 100%
Supervision :
Boumazouza Ryma (Airbus) et Ducoffe Mélanie (Airbus)
Pour postuler
Adresser CV + lettre de motivation :
ryma.boumazouza@airbus.com
melanie.ducoffe@airbus.com
Internship : FORMAL VERIFICATION OF MACHINE LEARNING ALGORITHMS ON ADVANCED AVIONICS HARDWARE – October 15, 2024
Machine Learning (ML) plays a pivotal role in the development of autonomous systems, including future generations of aircraft that will integrate advanced algorithms for enhanced capabilities, such as vision-based autonomous landing for drones and commercial aircraft. While these algorithms perform efficiently in cloud or data center environments, deploying them on autonomous vehicles presents significant challenges—especially in ensuring safety. In the field of aeronautics, every function, whether ML-based or not, must meet rigorous safety standards, even in the event of hardware failures.
Vision-based perception systems, which are critical for autonomous operations, demand immense computational power and high-bandwidth communications (e.g., from cameras). However, current avionics processors lack the necessary capacity to handle such workloads. As a result, new processing architectures, such as Component-off- the-shelf (COTS) GPUs and many-core processors, will be essential. Before these can be deployed, it’s crucial to study their hardware failure modes, understand how these failures could affect the ML algorithms they support, and develop safeguards to ensure safe execution.
Several existing works, such as [1], [2], and [3], have addressed these issues by formally modeling platform behavior in the presence of faults, along with the mitigation strategies designed to reduce the impact of these faults. These models can be analyzed using solvers to determine if the mitigations are sufficient to guarantee safe hardware operation under specified conditions.
Preliminary research has identified the Versatile Tensor Accelerator (VTA [4]) as a suitable candidate for further exploration of this problem. VTA is open hardware, meaning its hardware description is fully accessible and customizable. It is described using Chisel [5], an advanced high-level hardware description language built on Scala [6].
[1] Guinebert, I., Barrilado, A., Delmas, K., Galtié, F., & Pagetti, C. (2022, June). Quality of Fault Injection Strategies on Hardware Accelerator. In International Conference on Computer Safety, Reliability, and Security (pp. 222-236). Cham: Springer International Publishing.
[2]Faure-Gignoux, A, Delmas, K, Gauffriau, A, Pagetti, C. (2024) Methodology for formal verification of hardware.safety strategies using SMT. International conference on embedded software (EMSOFT)
[3] Dobis, A., Laeufer, K., Damsgaard, H. J., Petersen, T., Rasmussen, K. J. H., Tolotto, E., … & Schoeberl, M. (2023). Verification of chisel hardware designs with chiselverify. Microprocessors and Microsystems, 96, 104737.
[4] https://github.com/apache/tvm-vta [5] https://www.chisel-lang.org/
Tasks and Accountabilities :
The primary goal of this internship is to evaluate the effectiveness of a set of pre-selected formal verification methods on the VTA. The key steps include:
-
- Conducting a literature review to identify the most promising formal verification methods from the pre- selected set.
- Gaining proficiency with the toolset required for functional and cycle-accurate simulation of VTA executions.
- Developing a framework to run small portions of deep neural networks (DNNs) on both functional and cycle-accurate simulators.
- Extending the framework to verify formal properties using the selected methods.
- Assessing the expressiveness and scalability of the approach, initially focusing on specific parts of theVTA, and, if feasible, expanding to the full accelerator.
- Based on the experiments, formulating recommendations for future theoretical and practicaldevelopments required for full-scale safety validation of VTA-like accelerators.
Required skills
-
- Hardware description languages (advanced)
- Compilation, Computing architectures (intermediate)
- Formal verification (notions)
- Programming (advanced)
Desired period
March to September 2025
Type de contrat : stage
Durée du contrat : 5-6 months (march to September 2025)
Gratification : 624,22€/month
Niveau d’études requis : Bac+5
Expérience : non
Lieu de travail : ONERA Toulouse: 2 Av. Marc Pélegrin, 31000 Toulouse. (Toulouse)
Quotité du travail : 100%
Supervision :
Kevin Delmas (ONERA) and Anthony Faure-Gignoux (ONERA)
Pour postuler
Adresser CV + lettre de motivation :
Kevin.delmas@onera.fr
Anthony.faure-gignoux@onera.fr